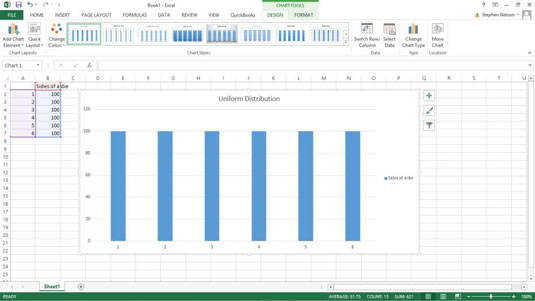
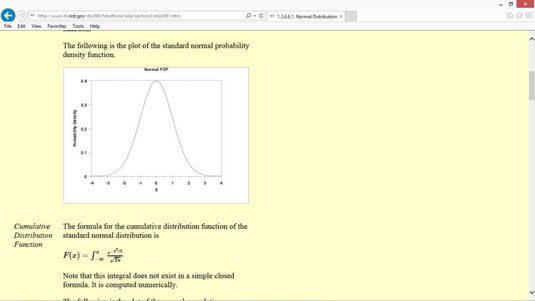
, excel - er et fantastisk redskab, når man skal bruge statistikker.hvis du aldrig har været udsat for statistik i skolen eller det ’ været 10 år eller to siden du var, så disse tips hjælper du bruger nogle af de statistiske værktøjer, der udmærker sig indeholder deskriptive statistikker er ligetil,., den første ting du bør vide, at en statistisk analyse og nogle statistiske foranstaltninger er ret ligetil.beskrivende statistikker, som omfatter ting som f.eks. dreje, tabel krydsningerne, samt nogle af de statistiske funktioner, mening endda nogen, der ’ ikke alle kvantitative. gennemsnit er ’ ikke så enkelt, nogle gange, når man bruger udtrykket, gennemsnit, hvad han sædvanligvis henviser er de mest almindelige gennemsnitlige måling, som er en ondskabsfuld., der har forståelse for, at udtrykket, gennemsnit, er upræcise, gør meget i excel - statistiske funktioner mere forståelig. for at gøre debatten mere konkrete, går ud fra, at du og’ leder på et lille sæt af værdier: 1, 2, 3, 4 og 5.som du måske ved, betyder i denne lille sæt af værdier er 3.man kan beregne den gennemsnitlige ved at sammenlægge alle numrene i sæt (1 + 2 + 3 + 4 + 5) og derefter dividere dette beløb (15) af det samlede antal værdier i den. (5), median, er den værdi, der adskiller de største værdier i det mindste værdier.i de data, der er 1, 2, 3, 4 og 5, er medianen. 3.værdien 3 adskiller de største værdier (4, 5) fra de mindste værdier (1 og 2), behøver du ikke at forstå forskellige gennemsnitlige målinger, men man bør huske på, at udtrykket, gennemsnit, er temmelig upræcis., standardafvigelser beskrive spredning, formel for standardafvigelse og logik, er ret let at forstå, en standardafvigelse, der beskriver, hvordan de værdier i et datasæt, der varierer i mener.den pæne ting om statistiske foranstaltninger, som en standardafvigelse, du ofte opnår reel indsigt i egenskaber af de data, som du og’ leder.en anden ting er, at med disse to dele af data, de ofte kan drage slutninger om data ved at se på prøver. en observation er en observation, observation, er en af de betingelser, som du og’ vil støde på, hvis du har læst noget om statistikker.en observation er bare en observation.en måde at definere begrebet bemærkning er denne: når du faktisk tildeler en værdi for en af dine tilfældige variabler, man skaber en bemærkning. en prøve er en undergruppe af værdier, en prøve, er en samling af bemærkninger fra en population.hvis man f.eks. skabe et datasæt, der registrerer den daglige høje temperaturer i dit nabolag, din lille samling af observationer er en prøve. i sammenligning, en prøve er ikke en befolkning.en befolkning, som omfatter alle mulige bemærkninger, inferential statistikker er seje, men kompliceret, hvis man ser på en prøve af værdier fra en population, og stikprøven er repræsentativ og store nok, kan man drage konklusioner om befolkning baseret på egenskaber af prøven. inferential statistikker, selv om meget stærkt, har to egenskaber, som du har brug for at vide:,,,,,,, nøjagtige spørgsmål,,,,,,, stejle indlæringskurve,,,,,,, sandsynlighedsfordeling funktioner er ikke altid forvirrende, p, robability fordelingsfunktion, det lyder ret svært, men du kan forstå intuitivt, hvad en sandsynlighedsfordeling funktion med et par gode eksempler. en fælles distribution, at du hører om i statistikker klasserfor eksempel er en t - distribution.en, distribution, er hovedsagelig en normal fordeling, undtagen med tungere, federe krone. en fælles sandsynlighedsfordeling funktion er en ensartet fordeling.i en ensartet fordeling, hver begivenhed har samme sandsynlighed for forekomst.det enestående ved denne fordeling er, at alt er temmelig darn plan.,, en anden fælles type sandsynlighedsfordeling funktion, er den normale fordeling, også kendt som en klokke kurve eller en gauss - distribution.,, en normal fordeling forekommer naturligt i mange situationer.for eksempel, intelligens, kvotienter (iq) distribueres normalt.,, parametre ikke er så kompliceret, at en parameter, er et input til sandsynlighedsfordeling funktion.med andre ord, den formel eller funktion eller ligning, som beskriver en sandsynlighedsfordeling kurve for input.i statistikker, er de råmaterialer, kaldes parametre. nogle sandsynlighedsfordeling funktioner behøver kun en enkelt parameter.for eksempel, at arbejde med en ensartet fordeling, alt du behøver, er antallet af værdier i datasættet.en seks sider dør, for eksempel, har kun seks muligheder., skævhed og kurtosis beskrive en sandsynlighedsfordeling ’ s form, et par andre nyttige statistiske hensyn at vide og kurtosis skævhed., skævhed, viser den manglende symmetri i sandsynlighedsfordeling.i en perfekt symmetrisk fordeling, som den normale fordeling, skævhed er lig med nul.hvis en sandsynlighedsfordeling læner sig til højre eller venstre, men det er noget andet end en skævhed, og den værdi, viser den manglende symmetri.,, kurtosis, kvantificerer tunghed i halen på en fordeling.i en normal fordeling, kurtosis er lig med nul.det, hale, er ting, som når ud til venstre eller højre.men hvis en hale i en fordeling er tungere end en normal fordeling, kurtosis er et positivt tal.hvis de haler i en fordeling er tyndere end i en normal fordeling, kurtosis er et negativt tal. konfidensintervaller synes kompliceret i starten, men er nyttige, sandsynlighed ofte forvirrer folk.en vigtig ting at forstå om tilliden er, at de ’ er forbundet med usikkerhed. et andet vigtigt at forstå om tilliden er, at jo større du din stikprøvestørrelse, mindre deres fejlmargen vil bruge den samme tillid plan. som et eksempel, siger du havde en google analyse data om to forskellige web - reklamer du ’ har for at fremme deres små virksomheder, og vil du vide hvor ad er mere effektiv.du kan bruge konfidensinterval formel for at regne ud, hvor længe din reklamer er nødt til at løbe, før google ’ er indsamlet tilstrækkelige data til, at du ved, som ad er meget bedre.,,