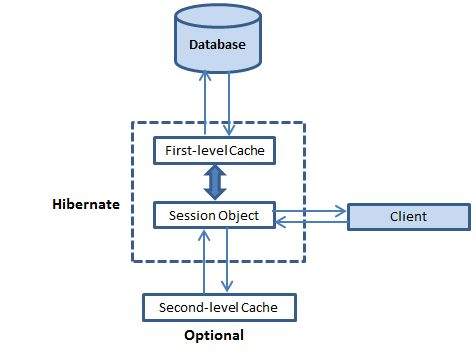
, caching er alt om anvendelse ydeevne optimering og det sidder mellem din ansøgning og databasen for at undgå, at antallet af database rammer så mange som muligt for at give en bedre ydeevne for udførelse af kritiske anvendelser., caching er vigtigt at gå i hi, som bruger en multilevel caching ordninger som forklaret nedenfor:,,, første niveau lager: for det første niveau cache er sessionen cache og er en obligatorisk lager, gennem hvilken alle anmodninger skal bestå.det objekt, holder en genstand ved egen kraft, før de forpligter det til databasen. hvis du udstede flere opdateringer til et objekt, gå i hi forsøger at forsinke det opdatering, så længe som muligt for at reducere antallet af ajourføre sql erklæringer.hvis du lukker den samling, alle de ting der blev skjult går tabt, og enten ved eller ajourføres i databasen. andet niveau cache:,, andet niveau cache er en valgfri cache og niveau i cache vil altid høres, før der er gjort forsøg på at finde et objekt i den anden plan lager.det andet niveau cache kan konfigureres på en pr. klasse og pr. samling grundlag og primært ansvarlig for caching objekter i møder. en tredjeparts cache kan anvendes sammen med gå i hi.en, org.hibernate.cache.cacheprovider interface, der, som skal gennemføres af gå med håndtag til cache gennemførelse. oplysninger fra niveau cache:, gå i hi også gennemfører et depot for spørgsmål resultsets, som integrerer tæt sammen med det andet niveau cache. er dette et valgfrit element og kræver yderligere to fysiske lager regioner, der har skjult forespørgsel resultater og timestamps, når en tabel, blev senest ajourført.det er kun til gavn for spørgsmål, der drives ofte med de samme parametre. det andet trin cache:, i hi anvender første niveau cache af misligholdelse, og du har intet at gøre med anvendelse af niveau 1 - lager.lad os gå direkte til den frivillige niveau 2 - lager.ikke alle klasser er omfattet af kravene, så det er vigtigt at være i stand til at deaktivere det andet niveau, lager, gå i hi andet niveau cache er oprettet i to trin.først skal du beslutte, hvilke concurrency strategi at anvende.efter det, vil du få cache udløb og fysiske lager attributter ved hjælp af cache udbyder. concurrency strategier: en concurrency strategi er en mægler, som ansvarlig for opbevaringen af data på lager og henter dem fra lager.hvis du vil gøre det muligt for et andet niveau, lager, du bliver nødt til at beslutte, om hver vedvarende klasse og indsamling, som lager concurrency strategi at anvende.,,,, statistik: brug af denne strategi for at læse for det meste data, hvor det er afgørende for at forhindre, at gamle data i samtidige transaktioner, i sjældne tilfælde af en ajourføring.,,,, læse, skrive: igen anvende denne strategi for at læse for det meste data, hvor det er afgørende for at forhindre, at gamle data i samtidige transaktioner, i sjældne tilfælde af en opdatering.,,,, nonstrict læse, skrive: denne strategi giver ingen garanti for overensstemmelse mellem lager og databasen.denne strategi, hvis data ikke ændringer og en lille sandsynlighed for statiske data ikke er af kritisk betydning.,,,,,,, læs: en concurrency strategi egnede for data, der aldrig ændrer sig.brug det til referencedata.,,, hvis vi skal bruge andet niveau caching for vores medarbejder, klasse, lad os tilføje kortlægningen element, der kræves for at fortælle gå til lager ansat tilfælde ved hjælp af read-write strategi. <?xml - version = "0" kodning = "utf - 8"?> <!gå doctype kortlægning af offentlige "- //i vinter hi /overvintrer kortlægning dtd //en" http: ////////////////////////////www.hibernate. org dtd hibernate-mapping-3.0. dtd "> < i vinter hi kortlægning > < klassenavn =" arbejdstager "tabel =" arbejdstager "> < meta - attribut =" klasse beskrivelse "> denne kategori omfatter ansatte i detaljer.< /meta - > < cache brug = "read-write" /> < id navn = "id" type = "int" kolonne = "id" > < generator klasse = "indfødte" /> < /id > < ejendomsnavn = "firstname" kolonne = "first_name" type = "streng" /> < ejendomsnavn = "lastname" kolonne = "last_name" type = "streng" /> < ejendomsnavn = "løn" kolonne = "løn" type = "int" /> < /klasse > < /overvintrer kortlægning >, brug = "read-write" attribut siger, gå til at anvende en read-write concurrency strategi for defineret cache., cache udbyder:, dit næste skridt efter at concurrency strategier, du vil bruge dine cache kandidat klasse er at vælge en cache udbyder.gå i hi tvinger dig til at vælge en enkelt cache leverandør til hele anvendelse., s.n. cache navn beskrivelse 1ehcacheit kan lager i hukommelse eller på cd og samlet caching, og det støtter frivilligt gå i hi forespørgsel følge lager.2 oscache støtter kravene til hukommelse og diskette i en enkelt jvm, med en rig, der udløber politikker og sætte spørgsmålstegn ved cache støtte.3 warmcache en klynge cache baseret på jgroups.den bruger samlet ugyldiggørelse, men ikke støtter den overvintrer forespørgsel cache - 4 jboss depot et fuldt transactional gentaget samlet cache også baseret på jgroups multicast bibliotek.det støtter replikation eller annullering synkron eller asynkron kommunikation og optimistiske og pessimistiske låsning.de sover forespørgsel cache støttes, hver cache udbyder, er ikke forenelig med hver concurrency strategi.følgende forenelighed matrix vil hjælpe dig med at vælge en passende kombination. strategi /leverandør læse onlynonstrictread skrive læse writetransactional ehcache x x x x x x x x x oscache swarmcache jboss cache - x, x, du vil indeholde en cache udbyder i hibernate.cfg.xml konfiguration fil.vi vælger ehcache som vores andet niveau cache udbyder:, <?xml - version = "0" kodning = "utf - 8"?> <!doctype i vinter hi konfiguration system "http: //////////////////////www.hibernate. org dtd hibernate-configuration-3.0. dtd" > < i vinter hi konfiguration > < samling fabrik > < ejendomsnavn = "gå i hi. dialekt" > org.hibernate.dialect.mysqldialect < /property > < ejendomsnavn = "gå i hi. forbindelse. driver_class" > com.mysql.jdbc.driver < /property > <!- antager studerende er databasen navn... > < ejendomsnavn = "gå i hi. forbindelse. url" > jdbc: mysql: //localhost /test < /property > < ejendomsnavn = "gå i hi. forbindelse. brugernavn" > root < /property > < ejendomsnavn = "gå i hi. forbindelse. kodeordet" > root123 < /property > < ejendomsnavn = "gå i hi. lager. provider_class"> org.hibernate.cache.ehcacheprovider < /property > <!- liste over xml - kortlægning af filer - > < kortlægning af = "arbejdstager. hbm. xml -" /> < /samling fabrik > < /overvintrer konfiguration >, nu, du er nødt til at præcisere de egenskaber af cache regioner.ehcache har sin egen konfiguration fil, ehcache. xml,, som bør være i classpath af ansøgningen.en cache konfiguration i ehcache.xml for arbejdstageren klasse kan se sådan ud:, < diskstore sti = "java. io. tmpdir" /> < defaultcache maxelementsinmemory = "1000" evig = "falske" timetoidleseconds = "120" timetoliveseconds = "120" overflowtodisk = "ægte" /> < cache navn = "arbejdstager" maxelementsinmemory = "500" evig = "ægte" timetoidleseconds = "0" timetoliveseconds = "0" overflowtodisk = "falske" /> det er det, vi nu har gjort det muligt for de ansatte på andet niveau caching klasse og gå i hi nu rammer den anden plan, lager, når du styrer en ansat eller, når du lader en ansat af id. du skal analysere dine alle klasser og vælge passende caching strategi for hver af disse klasser.på andet niveau caching deklassere udførelsen af anmodningen.det anbefales at benchmark din ansøgning først, uden at der er mulighed for caching, og senere gøre din velegnet caching, og kontrollere resultaterne.hvis kravene ikke er at forbedre systemets ydeevne, er der ingen grund til, at enhver form for caching. forespørgslen niveau cache:, at anvende forespørgslen lager, du skal aktivere det ved hjælp af, gå i hi. lager. use_query_cache = "ægte" ejendom i konfigurationen fil.ved fastsættelsen af denne ejendom til ægte, du sover skabe de nødvendige depoter til minde for forespørgslen og identifikator sæt. næste, at anvende forespørgslen lager, du bruger setcacheable (boolean) metode til forespørgslen klasse.for eksempel:, samling møde = sessionfactory. opensession(); forespørgsel spørgsmål = samling. createquery ("arbejdstager"); spørgsmål. setcacheable (korrekt); liste brugere = forespørgsel. list(); sessionfactory. closesession();, gå i hi støtter også meget finkornet cache støtte gennem begrebet en cache - regionen.en cache - regionen er en del af det lager, der er givet et navn. møde, møde = sessionfactory. opensession(); forespørgsel spørgsmål = samling. createquery ("arbejdstager"); spørgsmål. setcacheable (korrekt); spørgsmål. setcacheregion ("arbejdstager"); liste brugere = forespørgsel. list(); sessionfactory. closesession();, kode anvender den metode til at fortælle i vinter hi opbevarer og se til søgning i den ansattes område i depot.