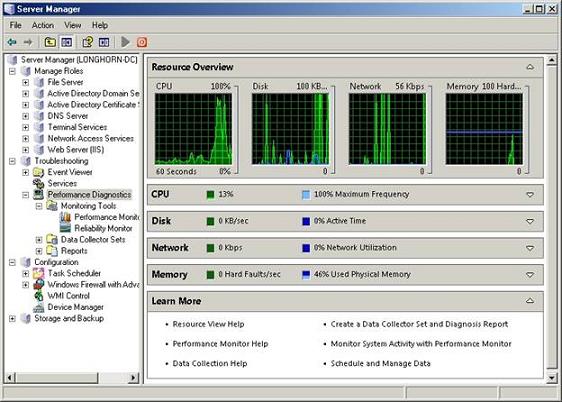
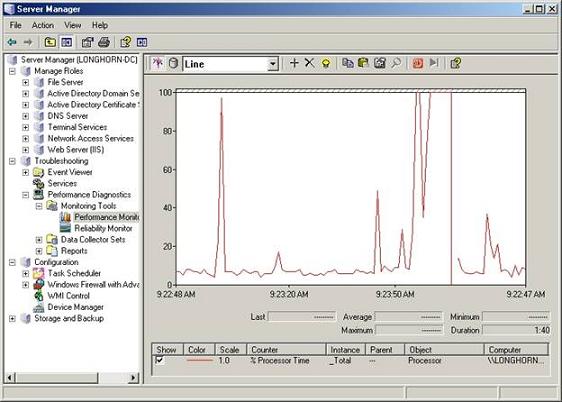
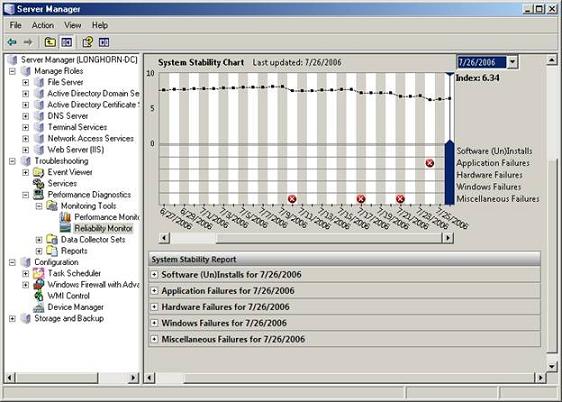
, i anden del af denne artikelserie, jeg viste dig, hvordan tilfælde log seer blevet moderniseret i longhorn - serveren, og hvordan tilfælde seer har været integreret i problemløsningssektion af serveren manager.i denne artikel, vil jeg gerne afslutte denne artikelserie ved at tale om de to andre elementer i problemløsningssektion. tjenesten kontrol manager og udførelsen diagnostik utility.,, tjenesten kontrol manager, lige under tilfælde man beholder i serveren manager problemløsningssektion er tjenesteydelser beholder.hvis du klikker på de tjenester, container, så de oplysninger, var af tjenesten kontrol manager vises.,, som de ved, service kontrol manager, er ikke nyt for longhorn server.det har eksisteret i hver version af windows server.jeg vil ikke spilde alt for meget tid på at tale om service kontrol manager for, ud fra hvad jeg kan se, det er stort set uændret siden windows server - 2003.jeg har dog vil i det mindste nævne, at tjenesten kontrol manager er nu tilgængeligt via problemløsningssektion af serveren manager.,, ydeevne, diagnose, hvad er mere interessant er udførelsen - beholder.hvis du har arbejdet med vinduer i et stykke tid, du er uden tvivl bekendt med udøvelsen at overvåge.gennemførelse overvågning er en del af udførelsen - del af serveren manager, men der er meget mere end det.,, hvis du vælger udførelsen - container, vil du se en ressource oversigt, svarende til den, der er vist i figur a. som i kan se på de tal, den øverste del af ressourcerne oversigt viser en række diagrammer, der viser cpu, diskette, netværk og hukommelse udnyttelse.,,,,, en:, ressource oversigt illustrerer grafisk, udnyttelse af dit system er primære komponenter, som du ser ud, vil du se, at lige under graferne er individuelle lister for cpu 'en, diskette, netværk og hukommelse.ved første øjekast, disse lister kan ikke synes at give dem alle de oplysninger, som du ikke kan komme ind på grafer over.men hvis du kigger til højre side af skærmen, ser du en pil i hver afdeling.hvis du klikker på de pile, ressource overblik vil give dem mere detaljerede oplysninger om anvendelsen af de enkelte komponenter.hvis man f.eks. tryk ned pil i cpu 'en del, du vil se en liste over alle de processer, der er i drift på serveren, og hvor meget cpu tid hver proces anvendes.på samme måde at trykke ned pil i den afdeling vil forårsage ressourcen overblik til at vise en liste over processer, der er adgang til den disk og indholdet af disk aktivitet, at de processer, der skaber.,, overvågningsværktøjer, hvis du går tilbage til konsollen træ og udvide udførelsen - container, vil du se, at det indeholder et overvågningsværktøj beholder.overvågningsredskaberne beholder ikke gør noget i sig selv, men den indeholder to forskellige værktøjer til overvågning og udførelsen overvåge og på pålidelighed overvåge.,,, ydeevne, overvåge,,, jeg vil gerne kort tale om de resultater, overvåge, bare i tilfælde af, at du ikke er bekendt med det.for dem af jer, der er bekendt med de resultater, overvåge, du kan springe frem til næste punkt.udførelsen overvåge synes ikke at have ændret sig meget siden windows server - 2003, bortset fra dens integration i serveren manager., resultater, overvåge, som vist i figur b, er et diagnostisk værdi, der er beregnet til at hjælpe dig med at løse problemer med hardware flaskehalse.hvis man ser på bunden af de tal, man kan se en check kasse ved siden af en tæller kaldet% processor.den tid tæller ser% forarbejdningsvirksomhed på serveren er samlet forarbejdningsvirksomhed anvendelse på visse intervaller og rapporter sine konstateringer på figur.,,,,, figur b: resultater, overvåge er en diagnostisk redskab, der anvendes til at lokalisere hardware flaskehalse,% forarbejdningsvirksomhed tid tæller kun er en af mange, eller måske endda tusinder af tilgængelige skranke.hver tæller, er konstrueret til at måle et bestemt aspekt af systemets ydeevne.der er typisk en tærskelværdi, der er forbundet med hver tæller, der repræsenterer problemfyldte præstationer.hvis de f.eks. ser på tallene, kan man se, at der er et par stænger i forarbejdningsvirksomhed aktivitet, som forarbejdningsvirksomheden, når op på 100%).disse stænger anses for normalt, fordi den gennemsnitlige forarbejdningsvirksomhed anvendelse bortset fra piggene er relativt lav.hvis den gennemsnitlige forarbejdningsvirksomhed anvendelse konsekvent var over 80%, ville det udgøre en forarbejdningsvirksomhed flaskehals.,, jeg ønsker ikke at gå for dybt ind i videnskab, overvågning af funktionsdygtighed, ville jeg i det mindste præsentere resultaterne overvåge til fordel for nogen, der aldrig har brugt den før.,,, pålidelighed, overvåge, den sidste ting jeg ønsker at vise er pålideligheden overvåge.pålideligheden og monitor er et fremragende redskab for de mennesker, der undertiden er nødt til at arbejde med ukendte systemer.for eksempel, hvis du tilfældigvis en konsulent og en klient beder dig om at komme og se på en server problem, så er et af de første spørgsmål, som du vil sikkert spørge kunden vil være om historien bag dette problem, eller vores server.problemet er, at den person, som du taler til, kan eller ikke kan give dem alle de oplysninger, du har brug for.for eksempel, den person kan samarbejde, men ikke rigtig ved, at serveren er historie.en anden mulighed er, at den person, der hedder du gjorde faktisk noget at give problemet og er flov over at indrømme det.det er hvor pålideligheden overvåge spiller ind.,, pålidelighed, overvåge, der vises i fig. c, har nogle forskellige ting for dig.den første ting, du vil nok se, når man ser på de tal, er den store figur.hvis man ser på den øverste del af figur, du vil se en masse prikker i forbindelse med en linje.punkterne er systemet stabilitetsindikator for hver dag.den grundlæggende idé bag dette indeks er indeksnummeret langsomt stiger for hver dag uden en fiasko, og uden at der er installeret eller uninstalling ansøgninger.,,,,, figur c:, pålidelighed, overvåge holder styr på forskellige fejl og begivenheder, der finder sted på deres server, jeg har ikke nogen dokumentation for pålidelighed, overvåge, - jeg kan ikke sige med sikkerhed, men ud fra hvad jeg har kunnet observere, stabilitetsindikatoren synes at gå ned efter du installere en ansøgning.indekset langsomt går lidt tilbage hver dag, som systemet viser sig at være stabil, mens ansøgningen.det samme sker, når enhver form for svigt.når et svigt stabilitetsindikatoren i dag falder drastisk.som tiden går, stabilitetsindikatoren i sidste ende vil stige, forudsat at ingen fiaskoer forekommer.,, vil de kunne se i den nederste del af figur, at fejlene er markeret på den dag, hvor de har fundet sted.bare ved at se på figur, kan du se, hvilken type fejl har været et problem i fortiden.du kan endda dobbelt klik på et bestemt ikke at få mere detaljerede oplysninger om de omstændigheder, der har givet anledning til manglende rapport. en ting, som jeg virkelig kunne lide om pålideligheden følge er, at det giver dem mulighed for at forudse problemer.for eksempel, hvis det ved at se på figur du mærke til, at der er en ansøgning om fiasko, der finder sted hver fire dage.hvis dette sker hele tiden, så er der et klart mønster til begivenheden.mange gange, at mønsteret er meget nyttig i problemløsning forskellige fiaskoer.der mangler i grafisk form gør det let at se, at du kunne mønstre miss.,, konklusion i denne artikel, jeg har drøftet de forskellige fejlsøgning værktøjer, som er indbygget i serveren manager.forhåbentlig, som du har læst denne artikelserie, du er begyndt at forstå, hvor vigtig den server manager vil være i longhorn server.husk på, at på det tidspunkt, at denne artikel er skrevet, longhorn server var stadig i beta - test.en af de ting, som jeg har talt om, vil kunne ændre på det tidspunkt, hvor longhorn server efterhånden er blevet løsladt.