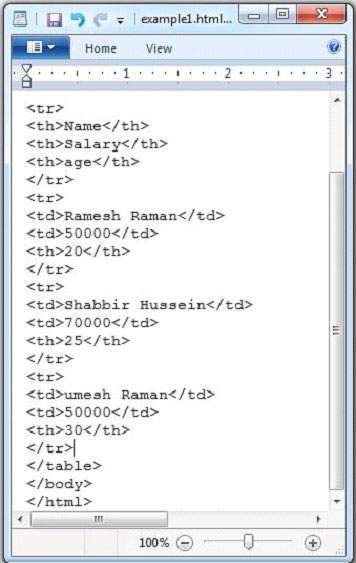
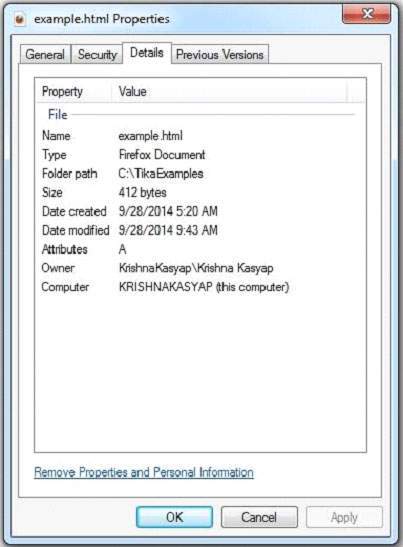
, er angivet nedenfor, er programmet til at udvinde indhold og metadata fra en html dokument., import java.io.file; import java.io.fileinputstream; import java.io.ioexception; import org.apache.tika.exception.tikaexception; import org.apache.tika.metadata.metadata; import org.apache.tika.parser.parsecontext; import org.apache.tika.parser.html.htmlparser; import org.apache.tika.sax.bodycontenthandler; import org.xml.sax.saxexception; offentlige klasse htmlparse {offentlige statisk tomrum vigtigste (sidste snor [] args) kaster ioexception, saxexception, tikaexception (//påvisning af filen type bodycontenthandler kontaktperson = nye bodycontenthandler(); metadata metadata = nye metadata(); fileinputstream inputtream = nye fileinputstream (ny database (f.eks. html "); parsecontext pcontext = nye parsecontext(); //html parser htmlparser htmlparser = nye htmlparser(); htmlparser. analysere (inputstream, kontaktperson, metadata, pcontext) system. println (" indholdet af dokumentet: "+ kontaktperson. tostring()); system. println (" metadata af dokumentet: "); snor [] metadatanames = metadata. names(); (string navn: metadatanames) (system. println (navn +": "+ metadata. kom (navn)}}}, medmindre ovennævnte kode, som htmlparse. java, og udarbejde det fra kommandoen omgående ved hjælp af følgende kommandoer:, javac htmlparse.java java htmlparse under givet er det billede af f.eks.tmb dokument.,, html dokument har følgende egenskaber:,, efter udførelsen af ovennævnte program, du vil få følgende output.,, output:,, indholdet af dokumentet: navn løn alder ramesh raman 50.000 20 shabbir hussein 70000 25 umesh raman 50.000 30 somesh 50.000 35 metadata af dokumentet: titel: html tabel header indholdskodning: windows-1252 content type: tekst /html; charset = windows-1252 dc: titel: http: //tabel header.