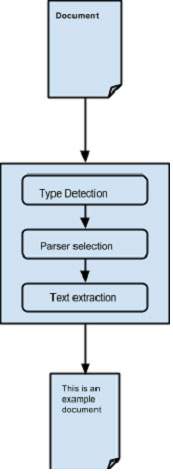
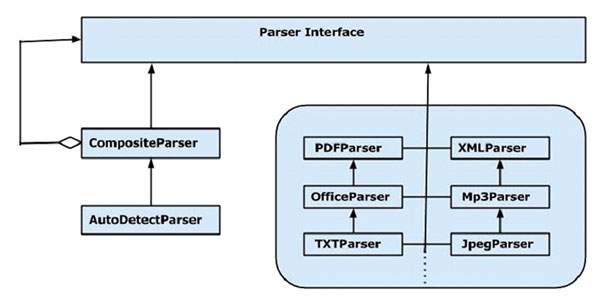
, tika anvender forskellige parser biblioteker, ekstrakt indhold fra givne parsers.det vælger den rigtige parser til udvinding af det pågældende dokument type., for parsing dokumenter, parsetostring() metode til tika facade klasse anvendes i almindelighed.nedenfor er angivet de foranstaltninger, der er involveret i parsing proces, og disse er anvendt af tika parsertostring() metode.,, informa den parsing proces:,,, i første omgang, når vi går et dokument til tika, den anvender en passende type påvisning tilgængelige mekanisme med det og påviser dokumenttype.,,,,, når dokumentet er kendt, det vælger en passende parser fra sin parser register.den parser register indeholder klasser, at gøre brug af eksterne biblioteker.,,,, så dokumentet er gået til at vælge den parser, der skal analysere indholdet, ekstrakt af teksten, og også kaste undtagelser for ulæselige formater.,,, - indhold ved udtrækning af tika, er angivet nedenfor, er programmet til udvinding af tekst fra en fil med tika facade klasse:, import java.io.file; import java.io.ioexception; import org.apache.tika.tika; import org.apache.tika.exception.tikaexception; import org.xml.sax.saxexception; offentlige klasse tikaextraction {offentlige statisk tomrum vigtigste (sidste snor [] args) kaster ioexception, tikaexception (//påtage sig sample.txt er i deres nuværende filkatalog file = nye fil ("stikprøve. txt"); //istantiating tika facade klasse tika tika = nye tika(); snor filecontent = tika. parsetostring (fil) system. println ("ekstraheret indhold:" + filecontent)), medmindre ovennævnte kode, som tikaextraction.java og løb fra kommandoen hurtig:, javac tikaextraction.java java tikaextraction, note, påtage sig sample.txt: har følgende indhold. hej elever velkommen til tutorialspoint, får man følgende output:, udvundet indhold: hej elever velkommen til tutorialspoint, indhold ekstraktion med parser grænseflade, parser pakke af tika giver flere grænseflader og klasser med, som vi kan analysere teksten dokument.nedenfor er blokdiagram for org.apache.tika.parser pakke.,, der er flere parser klasser, der er til rådighed, f.eks. pdf parser, mp3passer, officeparser osv. for at analysere de respektive dokumenter individuelt.alle disse kategorier af parser grænseflade,.,, compositeparser, i diagram viser tika er generelt parser klasser, compositeparser, og autodetectparser,.siden compositeparser klasse følger kompositkonstruktion mønster, du kan bruge en gruppe af parser tilfælde som en enkelt parser.den compositeparser klasse giver også adgang til alle klasser, at gennemføre parser grænseflade. autodetectparser, dette er en underklasse af compositeparser, og den giver automatisk type påvisning.ved hjælp af denne funktion, autodetectparser automatisk sender de indkommende dokumenter til de relevante parser klasser ved hjælp af sammensatte metode. parse() metode sammen med parsetostring(), kan du også bruge den parse() metode i parser grænseflade.en prototype af denne metode er vist nedenfor., analysere (inputstream strøm, contenthandler kontaktperson, metadata metadata, parsecontext sammenhæng) nedenstående tabel viser de fire objekter, der accepterer som parametre. s.no. formål og beskrivelse 1, inputstream stream, inputstream objekt, der indeholder indholdet af sagsakterne, 2,,, contenthandler kontaktperson, tika passerer dokument som xhtml indhold til den kontaktperson, derefter dokumentet er forarbejdet ved anvendelse af sax api - grænseflade.det giver effektiv efterbehandling af indholdet i et dokument., 3, metadata metadata, metadata - objekt anvendes både som en kilde og et mål for dokument metadata, 4, parsecontext sammenhæng, denne genstand er brugt i de tilfælde, hvor kunden anvendelse vil vælge den parsing proces.,, f.eks.: i betragtning af nedenfor, er et eksempel, der viser, hvordan parse() metode anvendes.,, trin 1:,, at anvende parse() metode i parser grænseflade, instantiate en af de kategorier, som gennemførelsen af denne grænseflade, der er enkelte parser klasser som pdfparser, officeparser, xmlparser osv. du kan bruge noget disse individuelle dokument parsers.alternativt kan du bruge enten compositeparser eller autodetectparser, der bruger alle de parser klasser internt og ekstrakter af indholdet af et dokument med en passende parser., parser parser = nye autodetectparser() og (eller) parser parser = nye compositeparser() og (eller) genstand for individuel parsers i tika bibliotek, trin 2:,, skabe en kontaktperson klasse objekt.nedenfor er de tre indhold står:, s.no. klasse og beskrivelse 1, bodycontenthandler, denne klasse vælger lig del af xhtml output og skriver, at indholdet til produktionen forfatter eller output strøm.så registret omdirigerer xhtml indhold til et andet indhold kontaktperson instans., 2, linkcontenthandler, denne klasse opdager og samler alle de h-ref mærker af xhtml dokument, og fremsender disse til brug af redskaber som web - larve., 3, teecontenthandler, denne klasse er ved hjælp af flere instrumenter, da vores samtidigt. målet er at få teksten indholdet af et dokument, instantiate bodycontenthandler som vist nedenfor: bodycontenthandler kontaktperson = nye bodycontenthandler (), trin 3:, skaber de metadata objekt som vist nedenfor, metadata metadata = nye metadata();,, trin 4:,, skabe en af de indgående strøm genstande, og giv din fil, der skal udtages til det. fileinputstream,, instantiate en fil genstand ved at filen vejsom parameter og vedtage dette objekt til fileinputstream klasse konstruktøren.,, note: vejen gik til filen formål bør ikke indeholde rum. problemet med disse input - stream - klasser, er, at de ikke støtter random access læser, der er nødvendige for at behandle nogle filformater, effektivt.for at løse dette problem, er tikainputstream tika., fil file = nye fil (filepath) fileinputstream inputstream = nye fileinputstream (fil) (eller) inputstream å = tikainputstream. kom (ny database (filnavn), trin 5:,, skabe en analysere forbindelse objekt som vist nedenfor: parsecontext forbindelse = nye parsecontext();,, trin 6:,, instantiate den parser objekt, påberåbe sig analysere metode, og give alle de genstande, der kræves som vist i prototypen nedenfor, parser. analysere (inputstream, kontaktperson, metadata, sammenhæng), er angivet nedenfor, er programmet for indhold, ekstraktion ved hjælp af parser grænseflade:, import java.io.file; import java.io.fileinputstream; import java.io.ioexception; import org.apache.tika.exception.tikaexception; import org.apache.tika.metadata.metadata, import - org.apache.tika.parser.autodetectparser; import org.apache.tika.parser.parsecontext; import org.apache.tika.parser.parser; import org.apache.tika.sax.bodycontenthandler; import org.xml.sax.saxexception; offentlige klasse parserextraction {offentlige statisk tomrum vigtigste (sidste snor [] args) kaster ioexception, saxexception, tikaexception (//påtage sig sample.txt er i deres nuværende filkatalog file = nye fil ("stikprøve. txt"); //analysere metode parametre parser parser = nye autodetectparser(); bodycontenthandler kontaktperson = nye bodycontenthandler(); metadata metadata = nye metadata(); fileinputstream inputstream = nye fileinputstream (fil); parsecontext forbindelse = nye parsecontext(); //parsing filen parsøh. analysere (inputstream, kontaktperson, metadata, forbindelse); system. println ("filens indhold:" + kontaktperson. tostring())), medmindre ovennævnte kode, som parserextraction.java og løb fra kommandoen hurtig:, javac parserextraction.java java parserextraction, assumre sample.txt indeholder følgende indhold, hej elever velkommen. for at tutorialspoint, det giver følgende output: filens indhold: hej elever velkommen til tutorialspoint,