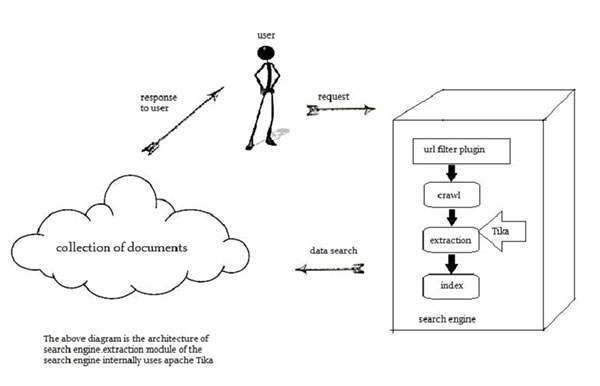
tika - oversigt over, hvad der er apache tika?,,, apache tika er et bibliotek, der er anvendt til dokumenttype påvisning og indhold ekstraktion fra forskellige filformater,.,,, internt tika anvender forskellige eksisterende dokument parsers og dokumenttype påvisning teknikker til påvisning og ekstrakt data.,,,, ved hjælp af tika, kan udvikle en universel type detektor og indhold - at udvinde både struktureret tekst samt metadata fra forskellige typer af dokumenter, som f.eks. regneark, tekst - dokumenter, billeder, pdfs og multimedier inputformater til en vis grad.,,,, tika danner en enkelt generiske api til parsing forskellige filformater.den bruger 83 eksisterende specialiserede parser ibraries for hver dokumenttype.,,, alle disse parser biblioteker er indkapslet i en fælles grænseflade, kaldet, parser grænseflade,.,,, hvorfor tika?i henhold til filext.com, der er omkring 15.000 til 51k indhold former, og tallet vokser dag for dag.data, der opbevares i forskellige formater såsom tekstdokumenter, excel - regneark, pdfs, billeder og multimedie - filer, for at nævne et par stykker.derfor, applikationer, som f.eks. søgemaskiner og content management systemer har brug for yderligere støtte for at lette udtrækning af data fra disse dokumenttyper.apache tika tjener dette formål, ved at yde en generisk api til påvisning og ekstrakt data fra forskellige filformater, apache tika ansøgninger, der er forskellige anvendelser, der gør brug af apache tika.her vil vi drøfte et par fremtrædende ansøgninger, som er meget afhængige af apache tika. søgemaskiner, tika er udbredt, og samtidig udvikle søgemaskiner til indeks teksten indholdet af digitale dokumenter.,,, af søgemaskiner edb - systemer, der er konstrueret til at søge oplysninger og indekseret dokumenter fra nettet.,,, larve er en vigtig komponent en søgemaskine, der kravler gennem internettet til at hente de dokumenter, der er indekseret med en indeksering teknik.derefter, larve overførsler disse indeks dokumenter til ekstraktion komponent.,,, det er en pligt for udvinding komponent er at trække teksten og metadata fra dokumentet.de udvundne indhold og metadata er meget nyttige for en søgemaskine.udvindingen bestanddel indeholder tika.,,,, det ekstraherede indhold er så videre til indexer af søgemaskiner, der bruger det til at bygge en søgning indeks.bortset fra dette søgemaskinen bruger den udtrukne indhold på mange andre måder.,,, dokument analyse, inden for kunstig intelligens, der er visse redskaber til at analysere dokumenter automatisk ved semantisk niveau og ekstrakt af alle former for oplysninger fra dem.,,,, på sådanne ansøgninger, dokumenter klassificeret på grundlag af den fremtrædende form i det ekstraherede dokumentets indhold.,,, disse værktøjer gør brug af tika for indhold udvinding at analysere dokumenter varierer fra almindelig tekst til digitale dokumenter.,,, digital forvaltning af aktiver, nogle organisationer forvalter deres digitale aktiver såsom fotografier, tegninger, bøger, musik og video med en særlig ansøgning kaldet digital asset management (dam).,,, der tagerhjælp af dokumenttype detektorer og metadata - at klassificere forskellige dokumenter.,,, indhold analyse, websteder som amazon anbefale nyligt løsladte indholdet af deres websted til individuelle brugere i overensstemmelse med deres egne interesser.for at gøre det, disse websteder, maskinindlæring teknikker, eller ved hjælp af sociale medier, websteder, som facebook for at få oplysninger, som kan lide og brugernes interesser.den indsamlede information vil være i form af html mærker eller andre formater, der kræver yderligere content type påvisning og - udvinding.,,,, til indhold analyse af et dokument, som vi har teknologi, som gennemfører maskinindlæring teknikker såsom, uima, og mahout,.disse teknologier er nyttige i klynger og analyse af data, i dokumenter,.,,,,, apache mahout, er en ramme, der giver ml algoritmer på apache hadoop – en cloud computing - platform.mahout giver en arkitektur, som efter visse klynger og - filtrering teknikker.ved at følge denne arkitektur, programmører kan skrive deres egen ml algoritmer til at udarbejde anbefalinger, ved at træffe forskellige tekst og metadata kombinationer.at give input til disse algoritmer, de seneste udgaver af mahout brug tika at udvinde tekst og metadata fra binære indhold.,,,, apache uima, analyserer og processer forskellige programmeringssprog og producerer uima kommentarer.det bruger til at udvinde tika annotator internt dokument tekst og metadata,.,,, historie, år udvikling 2006 idéen om tika var planlagt før lucene projekt forvaltningskomité.2006 begrebet tika og dens anvendelighed i jackrabbit - projektet blev drøftet.2007 tika trådte i apache rugemaskine.2008 versioner 0,1 og 0,2 blev løsladt og tika dimitterede fra rugemaskinen, til lucene delprojekt.2009 versioner 0, 3, 0, 4, og 5, blev frigivet.2010 version 0,6 og 0,7 blev løsladt og tika bestod i øverste apache - projektet.2011 tika 1 blev løsladt og bog om tika "tika i aktion" blev også offentliggjort i samme år.,