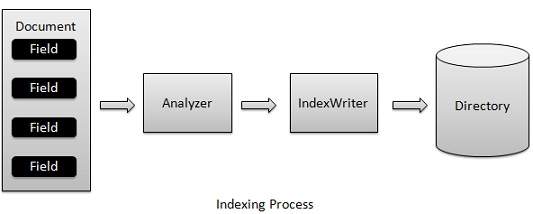
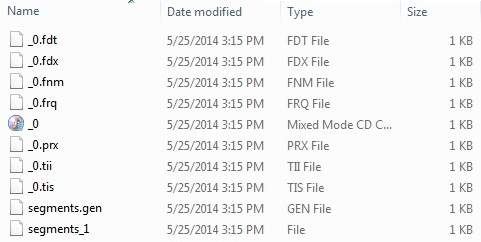
, indeksering proces, er et af de centrale funktioner, der er fastsat i lucene.følgende diagram viser indeksering proces og anvendelse af klasser.indexwriter er den mest vigtige og centrale del af indeksering proces.,, vi tilføje, dokument (er), der indeholder område (r), indexwriter, der analyserer de, dokument (er) ved hjælp af, analyzer, og så skaber /åbne /edit fortegnelser, som kræves og opbevare /opdatere dem i et register.indexwriter anvendes til at ajourføre eller skabe fortegnelser.det er ikke vant til at læse indekser. nu skal vi vise dig en trinvis proces for at få et kick start i forståelse med indeksering proces med en grundlæggende f.eks. skabe et dokument, skabe en metode til at få et lucene dokument fra en tekstfil.,,, skaber forskellige typer områder, der er central værdi par med nøgler som navne og værdier som indhold indekseres.,,, der er område analyseres eller ej.i vores tilfælde kun indholdet analyseres som det kan indeholde data, som f.eks. en, der er, er en osv., som ikke er nødvendige for at søge arbejde.,,, tilføje nye områder til det dokument, formål og returnerer det til den opringende metode.,,, privat dokument getdocument (file fil) gør ioexception (dokument = nye document(); //index filindhold område contentfield = nye område (luceneconstants.contents, nye filereader (fil)); //index filnavn område filenamefield = nye område (luceneconstants.file_name, fil. getname() område. butik. - ja, mark. indeks. not_analyzed); //index fil vej område filepathfield = nye område (luceneconstants.file_path, fil. getcanonicalpath() område. ja, field.ind butik.ex.not_analyzed); dokument. der tilsættes (contentfield); dokument. der tilsættes (filenamefield); dokument. der tilsættes (filepathfield); tilbage dokument;}, skabe en indexwriter,,, indexwriter klasse fungerer som et centralt element, der skaber /ajourfører fortegnelser i indeksering proces.,,, skabe genstand for indexwriter.,,, skabe en lucene register, der bør påpege, hvor fortegnelser opbevares.,,, sæt den indexwriter objekt skabt med indeks over en standard analyzer under version oplysninger og andre påkrævede /fakultative parametre.,,, private indexwriter forfatter, offentlige indexer (string - indexdirectorypath) kaster ioexception (//denne database vil indeholde de fortegnelser fortegnelse indexdirectory = fsdirectory. åben (nye fil (ind.exdirectorypath)); //skabe indexer forfatter = nye indexwriter (indexdirectory, nye standardanalyzer (version. lucene_36), sandt, indexwriter. maxfieldlength. ubegrænset)}, start indeksering proces, private tomrum indexfile (file fil) kaster ioexception {system. println ("indeksering" + fil. getcanonicalpath()); dokument = getdocument (fil); forfatter. adddocument (nummer)}, f.eks. ansøgning, lad os skabe en test lucene anvendelse for at teste indeksering proces. stepdescription 1create et projekt med et navn, lucenefirstapplication under en pakke, com.tutorialspoint.lucene, som forklaret i den, lucene - første ansøgning, kapitel.du kan også bruge projektet skabt i, lucene - første ansøgning, kapitel som sådan i dette kapitel at forstå indeksering proces.2create, luceneconstants. java,,, textfilefilter.java, og indexer.java, som forklaret i den, lucene - første ansøgning, kapitel.hold resten af filerne uændret.3create, lucenetester.java, som nævnt nedenfor.4clean og opbygge anvendelse for at sikre, at erhvervslivet logik er at arbejde som pr. kravene.,, luceneconstants -, denne klasse anvendes til at give forskellige konstanter anvendes i stikprøven anvendelse., pakke com.tutorialspoint.lucene; offentlige klasse luceneconstants {offentlige statisk sidste snor indhold = "indholdet" offentlige statisk sidste snor file_name = "filnavn" offentlige statisk sidste snor file_path = "filepath" offentlige statisk endelig udg. int max_search = 10), textfilefilter -, denne klasse anvendes som en. txt fil filter, pakke com.tutorialspoint.lucene; import java.io.file; import java.io.filefilter; offentlige klasse textfilefilter gennemfører filefilter {@ tilsidesætte offentlige boolean acceptere (sag pathname) {tilbage pathname. getname(). tolowercase(). endswith (". txt");), indexer -, denne klasse anvendes to indeks rådata, således at vi kan få den søgbare ved hjælp af lucene bibliotek., pakke com.tutorialspoint.lucene; import java.io.file; import java.io.filefilter; import java.io.filereader; import java.io.ioexception; import org.apache.lucene.analysis.standard.standardanalyzer; import org.apache.lucene.document.document; import org.apache.lucene.document.field; import org.apache.lucene.index.corruptindexexception; import org.apache.lucene.index.indexwriter; import org.apache.lucene.store.directory; import org.apache.lucene.store.fsdirectory; import org.apache.lucene.util.version; offentlige klasse indexer (private indexwriter forfatter. offentlige indexer (string - indexdirectorypath) kaster ioexception (//denne fortegnelse skal indeholdefortegnelser over indexdirectory = fsdirectory. åben (ny database (indexdirectorypath)); //skabe indexer forfatter = nye indexwriter (indexdirectory, nye standardanalyzer (version. lucene_36), sandt, indexwriter. maxfieldlength. ubegrænset)} offentlige tomrum close() kaster corruptindexexception, ioexception {forfatter. close();} privat dokument getdocument (file fil) kaster ioexception (dokument = nye document(); //index filindhold område contentfield = nye område (luceneconstants.contents, nye filereader (fil)); //index filnavn område filenamefield = nye område (luceneconstants.file_name, fil. getname() område. butik. - ja, fik. indeks. not_analyzed); //index fil vej inden filepathfield = nye område (luceneconstants.file_path, fil. getcanonicalpath() område. butik. - ja, mark. indeks. not_analyzed); dokument. der tilsættes (contentfield); dokument. der tilsættes (filenamefield); dokument. der tilsættes (filepathfield); tilbage dokument;} private. indexfile (file fil) kaster ioexception {system. println ("indeksering" + fil. getcanonicalpath()) dokument = getdocument (fil); forfatter. adddocument (nummer)} offentlige int createindex (string - datadirpath, filefilter filter) kaster ioexception (//får alle filer i data filkatalog. [...] filer = nye fil (datadirpath). listfiles(); (fil fil: filer) (hvis (!fil. isdirectory() &&!fil. ishidden() &&fil. exists() &&fil. canread() &&filter. accepterer (fil)) (indexfile (fil)}} tilbage forfatter. numdocs();}},, lucenetester -, denne klasse anvendes til at teste den indeksering evne til lucene bibliotek., pakke com.tutorialspoint.lucene; import java.io.ioexception; offentlige klasse lucenetester {snor indexdir = e: ¶ ¶ ¶ ¶ lucene indeks "snor datadir = e: ¶ ¶ ¶ ¶ lucene data". indexer indexer; offentlige statisk tomrum vigtigste (string [] args) (lucenetester tester, tester prøve (= nye lucenetester(); - tester. createindex();} fangst (ioexception e) (f. printstacktrace();}} private tomrum 'ateindex() kaster ioexception {indexer = nye indexer (indexdir); int numindexed; lange starttime = system. currenttimemillis(); numindexed = indexer. createindex (datadir, nye textfilefilter()); lange endtime = system. currenttimemillis(); indexer. close(); system. println (numindexed + "fil indeks, der:" + (endtime starttime) + "ms")), data & indeks over oprettelse, jeg har brugt 10 tekstfiler ved navn fra record1.txt til record10.txt indeholder blot navne og andre oplysninger om studerende og læg dem i registret, e:. lucene. data. test data.et indeks over vej bør oprettes, e:. lucene. indeks.efter at have arbejdet med dette program, kan du se listen over indeks filer oprettet i den mappe,., at programmet:, når du er færdig med at kilde, at skabe de rå data, data, fortegnelse og indeks fortegnelse, du er klar til dette skridt, som er at samle og kører dit program.for at gøre dette, hold lucenetester - fil regning aktive og anvende enten, løb, valgmulighed på solformørkelsen ide eller anvendelse, ctrl + f11, til at udarbejde og løbe din, lucenetester, anvendelse.hvis alt er i orden med din ansøgning, vil dette aftryk følgende budskab i formørkelse ide 's konsol:, indeksering e:. lucene. data. record1.txt indeksering e:. lucene. data. record10.txt indeksering e:. lucene. data. record2.txt indeksering e:. lucene. data. record3.txt indeksering e: lucene. data. det record4.txt indeksering e:. lucene. data. record5.txt indeksering e:. lucene. data. record6.txt indeksering e:. lucene. data. record7.txt indeksering e:. lucene. data. record8.txt indeksering e:. lucene. data. record9.txt 10 fil indekseret, tiden taget: 109 m, når du har kørt programmet med succes, vil du have følgende indhold i din, indeks fortegnelse:,,,