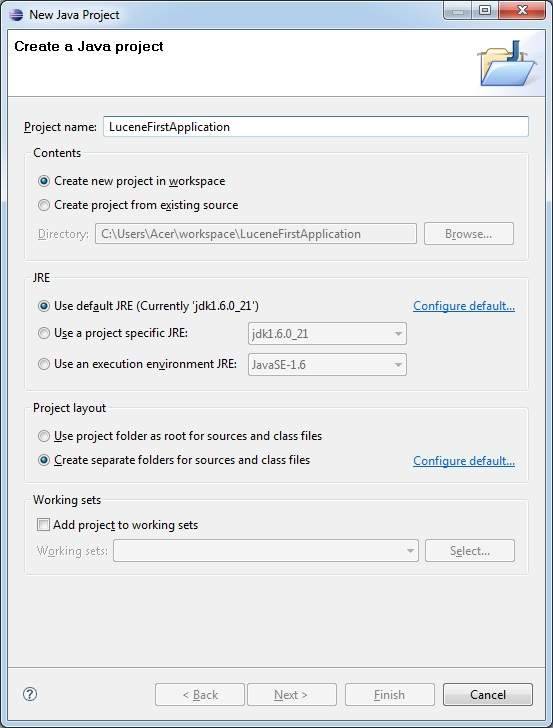
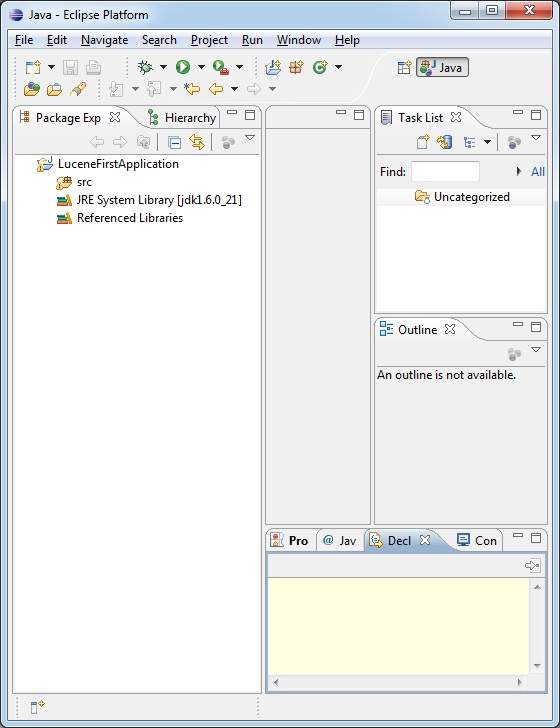
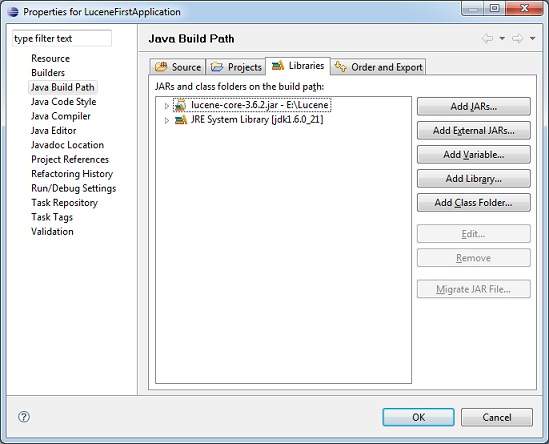
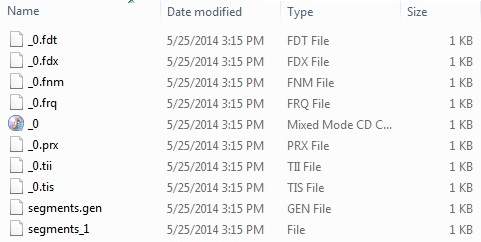
, lad os starte med konkrete programmer med lucene rammer.før du begynder at skrive din første eksempel med lucene ramme, skal du sikre dig, at du har arrangeret jeres lucene miljø korrekt, som beskrevet i lucene - miljø fælde tutor.jeg går også ud fra, at du har lidt praktisk erfaring med formørkelse ide., så lad os gå videre til at skrive en simpel søgning ansøgning, der trykker antal søgning resultat.vi vil også se listen over de fortegnelser, der er skabt i løbet af denne proces, trin 1 - skabe java - projektet: det første skridt er at skabe en enkel java - projekt med formørkelse ide.følg den mulighed, fil - > nye - > - projektet, og endelig at udvælge, java - projektet, troldmand fra troldmanden liste.nu hedder dit projekt, som lucenefirstapplication med troldmanden vindue som følger:,, når projektet er skabt med succes, vil du have følgende indhold i deres projekt opdagelsesrejsende:,,, trin 2 - tilføje krævede biblioteker: som andet skridt, lad os tilføje lucene kerne ramme bibliotek i vores projekt.for at gøre dette, ikke klik på dit projekt navn, lucenefirstapplication, og følg så efter følgende mulighed i forbindelse menu: bygge vej - > konfigurere bygge vej, til at udvise java bygge vej vindue som følger:,, bruger nu tilføje eksterne krukker, button, der er til rådighed under, biblioteker, regning at tilføje følgende centrale glas fra lucene anlæg fortegnelse:,,, lucene-core-3.6.2, trin 3 - skabe kilde filer:, nu skal vi skabe reelle kilde filer på, lucenefirstapplication, projekt.først er vi nødt til at skabe en pakke kaldet, kom. tutorialspoint. lucene,.for at gøre dette, ikke klik på src, pakke opdagelsesrejsende afsnit og følge den valgmulighed, nye - > pakke. næste, vi vil skabe, lucenetester.java og andre java klasser i com.tutorialspoint.lucene pakke.,, luceneconstants -, denne klasse anvendes til at give forskellige konstanter anvendes i stikprøven anvendelse., pakke com.tutorialspoint.lucene; offentlige klasse luceneconstants {offentlige statisk sidste snor indhold = "indholdet" offentlige statisk sidste snor file_name = "filnavn" offentlige statisk sidste snor file_path = "filepath" offentlige statisk endelige int max_search = 10), textfilefilter -, denne klasse anvendes som. txt fil filter, pakke com.tutorialspoint.lucene; import java.io.file; import java.io.filefilter, -der textfilefilter gennemfører filefilter (klasse @ tilsidesætte offentlige boolean acceptere (sag pathname) {tilbage pathname. getname(). tolowercase(). endswith (". txt")), indexer -, denne klasse anvendes til indeks rådata, således at vi kan få den søgbare ved hjælp af lucene bibliotek., pakke com.tutorialspoint.lucene; import java.io.file; import java.io.filefilter; import java.io.filereader; import java.io.ioexception; import org.apache.lucene.analysis.standard.standardanalyzer; import org.apache.lucene.document.document; import org.apache.lucene.document.field; import org.apache.lucene.index.corruptindexexception; import org.apache.lucene.index.indexwriter; import org.apache.lucene.store.directory; import org. apache. lucene. butik.sdirectory; import org.apache.lucene.util.version; offentlige klasse indexer (private indexwriter forfatter, offentlige indexer (string - indexdirectorypath) kaster ioexception (//denne database vil indeholde de fortegnelser over indexdirectory = fsdirectory. åben (ny database (indexdirectorypath)); //skabe indexer forfatter = nye indexwriter (indexdirectory, nye standardanalyzer (version. lucene_36), sandt, indexwriter. maxfieldlength. ubegrænset)} offentlige tomrum close() kaster corruptindexexception, ioexception {forfatter. close();} privat dokument getdocument (file fil) kaster ioexception (dokument = nye document(); //index filindhold område contentfield= nye område (luceneconstants.contents, nye filereader (fil)); //index filnavn område filenamefield = nye område (luceneconstants.file_name, fil. getname() område. butik. - ja, mark. indeks. not_analyzed); //index fil vej inden filepathfield = nye område (luceneconstants.file_path, fil. getcanonicalpath(), mark. - butik. ja, mark. indeks. not_analyzed); dokument. der tilsættes (contentfield); dokument. der tilsættes (filenamefield); dokument. der tilsættes (filepathfield); tilbage dokument;} private tomrum indexfile (file fil) kaster ioexception {system. println ("indeksering" + fil. getcanonicalpath()) dokument = getdocument (fil); forfatter. adddocument (dok.);} offentlige int createindex (string - datadirpath, filefilter filter) kaster ioexception (//får alle filer i data filkatalog. [...] filer = ny fil (datadirpath). listfiles(); (file fil: filer) (hvis (!fil. isdirectory() &&!fil. ishidden() &&fil. exists() &&fil. canread() &&filter. accepterer (fil)) (indexfile (fil)}} tilbage forfatter. numdocs();}}, søger -, denne klasse anvendes til at søge de fortegnelser, der er skabt af indexer til at søge om indhold, pakke com.tutorialspoint.lucene. java.io.file, import, import - java.io.ioexception; import org.apache.lucene.analysis.standard.standardanalyzer; import org.apache.lucene.document.document; import org.apache.lucene.index.corruptindexexception; import org.apache.lucene.queryparser.parseexception; import org.apache.lucene.queryparser.queryparser; import org.apache.lucene.search.indexsearcher; import org.apache.lucene.search.qu- hver; import org.apache.lucene.search.scoredoc; import org.apache.lucene.search.topdocs; import org.apache.lucene.store.directory; import org.apache.lucene.store.fsdirectory; import org.apache.lucene.util.version; offentlige klasse søger {indexsearcher indexsearcher; queryparser queryparser; forespørgsel spørgsmål; offentlige søger (string - indexdirectorypath) kaster ioexception {adresseregister indexdirectory = fsdirectory. åben (ny database (indexdirectorypath)); indexsearcher = nye indexsearcher (indexdirectory); queryparser = ny queryparser (version.lucene_36, luceneconstants.contents, nye standardanalyzer (version. lucene_36)} offentlige topdocs søgning (string - searchquery)s ioexception, parseexception {forespørgsel = queryparser. analysere (searchquery); tilbage indexsearcher. søgning (spørgsmål, luceneconstants. max_search)} offentligt dokument getdocument (scoredoc scoredoc) kaster corruptindexexception, ioexception {tilbage indexsearcher. doc (scoredoc. doc)} offentlige tomrum close() kaster ioexception {indexsearcher. close();}},, lucenetester -, denne klasse anvendes til at teste indeksering og søgning i stand til lucene bibliotek., pakke com.tutorialspoint.lucene; import java.io.ioexception; import org.apache.lucene.document.document; import org.apache.lucene.queryparser.parseexception; import org.apache.lucene.search.scoredoc; import org.apache.lucene.search.topdocs; offentlige klasse.cenetester {snor indexdir = e: ¶ ¶ ¶ ¶ lucene indeks "snor datadir = e: ¶ ¶ ¶ ¶ lucene data". indexer indexer; søger søger; offentlige statisk tomrum vigtigste (string [] args) (lucenetester tester, tester prøve (= nye lucenetester(); - tester. createindex(); - tester. søgning ("dig");} fangst (ioexception e) (f. printstacktrace();} fangst (parseexception e) (f. printstacktrace();}} private tomrum createindex() kaster ioexception {indexer = nye indexer (indexdir); int numindexed; lange starttime = system. currenttimemillis(); numindexed = indexer. createindex (datadir, nye textfilefilter()); længe endtime = system. currenttimemillis();indexer. close(); system. println (numindexed + "fil indeks, der:" + (endtime starttime) + "ms");} private tomrum søgning (string - searchquery) kaster ioexception, parseexception {søger = ny søger (indexdir); lange starttime = system. currenttimemillis(); topdocs rammer = søger. eftersøgning (searchquery); lange endtime = system. currenttimemillis(); system. println (hits.totalhits + "- dokumenter.tid: "+ (endtime - starttime)); (scoredoc scoredoc: hits. scoredocs) (dokument doc = søger. getdocument (scoredoc) system. println (" fil: "+ dok. kom (luceneconstants. file_path)} søger. close();}}, trin 4 - data & indeks over oprettelse, jeg har brugt 10 tekstfiler ved navn fra record1.txt til record10.txt indeholder blot navne og andre oplysninger om studerende og læg dem i registret, e:. lucene. data. test data.et indeks over vej bør oprettes, e:. lucene. indeks.efter at have arbejdet med dette program, kan du se listen over indeks filer oprettet i den mappe, løntrin 5 - styrer programmet:, når du er færdig med at kilde, at skabe de rå data, data, fortegnelse og indeks fortegnelse, du er klar til dette skridt, som er at samle og kører dit program.for at gøre dette, hold lucenetester - fil regning aktive og anvende enten, løb, valgmulighed på solformørkelsen ide eller anvendelse, ctrl + f11, til at udarbejde og løbe din, lucenetester, anvendelse.hvis alt er i orden med din ansøgning, vil dette aftryk følgende budskab i formørkelse ide 's konsol:, indeksering e:. lucene. data. record1.txt indeksering e:. lucene. data. record10.txt indeksering e:. lucene. data. record2.txt indeksering e:. lucene. data. record3.txt indeksering e: lucene. data. det record4.txt indeksering e:. lucene. data. record5.txt indeksering e:. lucene. data. record6.txt indeksering e:. lucene. data. record7.txt indeksering e:. lucene. data. record8.txt indeksering e:. lucene. data. record9.txt 10 fil indekseret, tiden taget: 109 ms - 1 - dokumenter.tid: 0 fil: e:. lucene. data. record4.txt, når du har kørt programmet med succes, vil du have følgende indhold i din, indeks fortegnelse:,,,